

I’ve recently had to do a lot of work on a set of data relating to my bank account transactions, which required a great deal of text manipulation, and working with several regular expressions. My bank doesn’t believe that giving their customers access to digital copies of their account and transaction history is important, and they only make available images (stored in PDFs) of past statements which have been posted. Because of this, I had to use Optical Character Recognition software to extract text from the images, fix by hand all the errors in the resulting output, and then manually structure the data into columns and rows by using regular expressions (as my OCR software didn’t detect them). To make matters worse, the images provided by my bank had a large text watermark on each one, written diagonally across the page stating “duplicate”. All contents of the spreadsheet which came into contact with this text was unreadable during OCR, and had to fixed by hand.
Once the data was successfully extracted and structured, I still had a problem however – my bank chooses to list each date only once, and so most of the listed transactions for my account had no date associated with them. The date is critical for the data to be useful to me, and I couldn’t sort or further analyse the accounts without knowing the date that each transaction had taken place. After some thought, I decided use a regular expression to fix the problem.
Problem
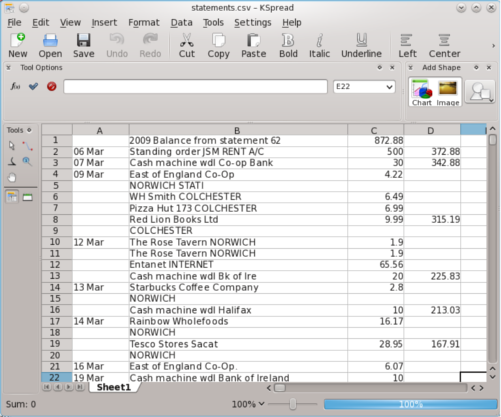
A spreadsheet with thousands transactions, one per row, where the date of each transaction is listed only once, with all following dates of that transaction missing a date (transactions were listed in date order). Before further processing the data (sorting, analysing) I needed to ensure that each transaction had its own date listed in the correct column.
Solution
By using regular expressions in KDE’s Kate text editor, I was able to quickly associate all rows with the correct date. I searched for empty cells which should have housed a date, and for each one took the date from the transaction above. I repeated this until each row had its own date.
The regex that I used (note that Kate wont accept pattern delimiters, switches, or greediness operators):
find: n([0-9]|[0-9][0-9]) (jan|feb|mar|apr|may|jun|jul|aug|sep|oct|nov|dec);(.*)n;
replace: n1 2;3n1 2;

The pattern finds all dates in the correct format and which begin the row, are contained within a cell (I used semicolon ; cell delimiters to avoid confusion with decimals and thousands in this CSV), and are followed by a row which does not contain a transaction date (ie the first cell is empty, and the newline starts with a cell delimiter ; ).
Each time the pattern is found, the matching text is replaced with the same line and an altered version of the first cell of the following line. The replace pattern inserts a duplicate of the date found in the first line into the first cell of the following line, thereby copying the date from one to the next.
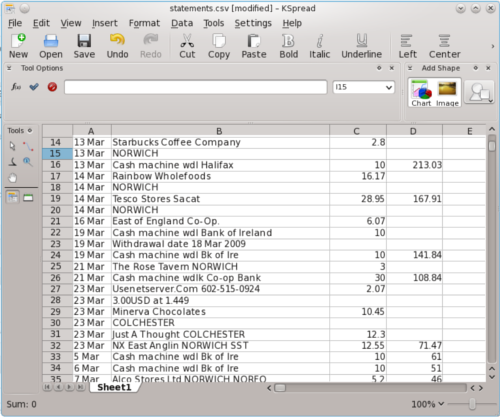
Having entered these patters into Kate’s find and replace fields I clicked on “replace all” several times, until no more matches were found, meaning that all transactions now had a date associated with them, listed in the correct table column at the start of each new line.
Result
My spreadsheet now contains a complete dataset, with each transaction correctly dated. I can sort the data as I wish (by price, incoming or outgoing, location, business, etc.) and easily manipulate it in preparation for submitting my tax return.
So, what do you think ?